Lab 8: Moooogle
NOTE: if you want to get started before we create partner repositories, you can download the starter code here.

One of the most impactful computer applications in the history of computing is the search engine. A search engine is a program that allows a user to enter in a query, e.g., “why are williams college colors purple and gold?”, and quickly obtain a relevant answer. Speed and relevance are two key parts of a search engine, and both are made possible by clever use of data structures. Before search engines, finding relevant content on the Internet was difficult
In this lab, we will explore using a hash table to build a search engine. Hash tables, in a slightly different form (a “distributed hash table”), are actually what search providers like Google, Bing, and DuckDuckGo use.
A search engine is composed of two parts:
- an indexer (aka, a crawler), and
- a query interface.
You will implement both of these parts in this lab.
This assignment has a few objectives:
- to explore the use of the key-value store ADT, and specifically, to utilize a hash table;
- to build a real-world application where the asymptotic properties of hash tables are essential; and
- to understand how the \(TF.IDF\) algorithm works.
In the end, you will produce a command-line tool that will return the \(k\) most relevant documents for a given query. For example, when searching for the five most relevant dog-related documents in a set of documents about UFOs, we obtain:
$ java SearchEngine "dog" ufo 5
ufo/UFOBBS/3000/3276.ufo -> 0.7040213308206384
ufo/UFOBBS/1000/1151.ufo -> 0.5084598500371277
ufo/UFOBBS/1000/1309.ufo -> 0.5084598500371277
ufo/UFOBBS/1000/1135.ufo -> 0.3520106654103192
ufo/UFOBBS/1000/1018.ufo -> 0.3010617533114572
and, looking at the top-ranked document, you can see that it is indeed dog-related:
SUBJECT: CANINE IMPLANTS ! FILE: UFO3276
...
Wed 10 Mar 93 21:04
By: Sheldon Wernikoff
To: All
Re: Canine Implants!
----------------------------------------------------------------------
The following article is from:
Chicago Computers & Users, February 1993, pg 4; published by
KB Communications (312)-944-0100. This publication is
available at no cost throughout the Chicago metropolitan area.
-----------------------------------------------------------------
"Iditarod sled dogs to be identified with computer chips"
...
What a Search Engine Does
Computer users often find themselves faced with the necessity of finding a small set of relevant documents from among a large set of documents, the greater number of which are irrelevant. This task, called information retrieval, is something you probably do dozens of times a day. For example, finding relevant webpages on the Internet is a form of information retrieval. Imagine how difficult the Internet would be to use if we did not have search engines! Believe it or not, in the 1990s, a popular way of finding information was to browse an online directory of all websites. The human effort required to maintain such a directory is infeasible now given the size of the modern Internet.
Clearly, what is needed is a piece of software that helps us find what we are looking for. For example, when looking for documents related to “the strongest pokemon”, most of the documents on the Internet are about something else. What we want is an algorithm that asks a computer to rank a set of documents by their relevance to a given search query.
Unfortunately, developing such an algorithm is not as simple as it seems.
One simple approach eliminates those documents that don’t contain the words in our query: “the”, “strongest”, and “pokemon”. However, because most documents still contain the word “the”, many documents are likely to remain.
Another simply counts the occurrences of terms from a search query in a set of documents and then returns the documents where such words are most frequent. In our case, it returns documents with many instances of “the”, “strongest” and “pokemon”. Again, in English, the most relevant words are rarely the most frequent. Words like “the”, “and”, “a”, and “of”—called stop words—appear in virtually all documents, but have little bearing on their content. The word “strongest” may actually be one of the least frequent words in a document where strength is an important concept.
One last bad approach filters out stop words. Unfortunately, aside from the most common words (like “the”), there is little agreement as to what constitutes a stop word, since some frequent words are relevant.
Fortunately, there are better algorithms. We will explore one of thost better methods, called \(TF.IDF\), in this lab.
What You Need to Do
You will need to implement tf, idf, tfidf, and score methods in order to build a search engine, and you will use those methods to compute scores for a set of documents given a user search query. To make computing these statistics efficient, you will need to use the structure5.Hashtable class. Your search engine will index all of the terms in each document in the given directory, counting terms and storing them in a table.
When you are done indexing, your completed table should resemble the following figure. Note that the entries and counts shown here are for illustrative purposes; their exact placements and values will vary.
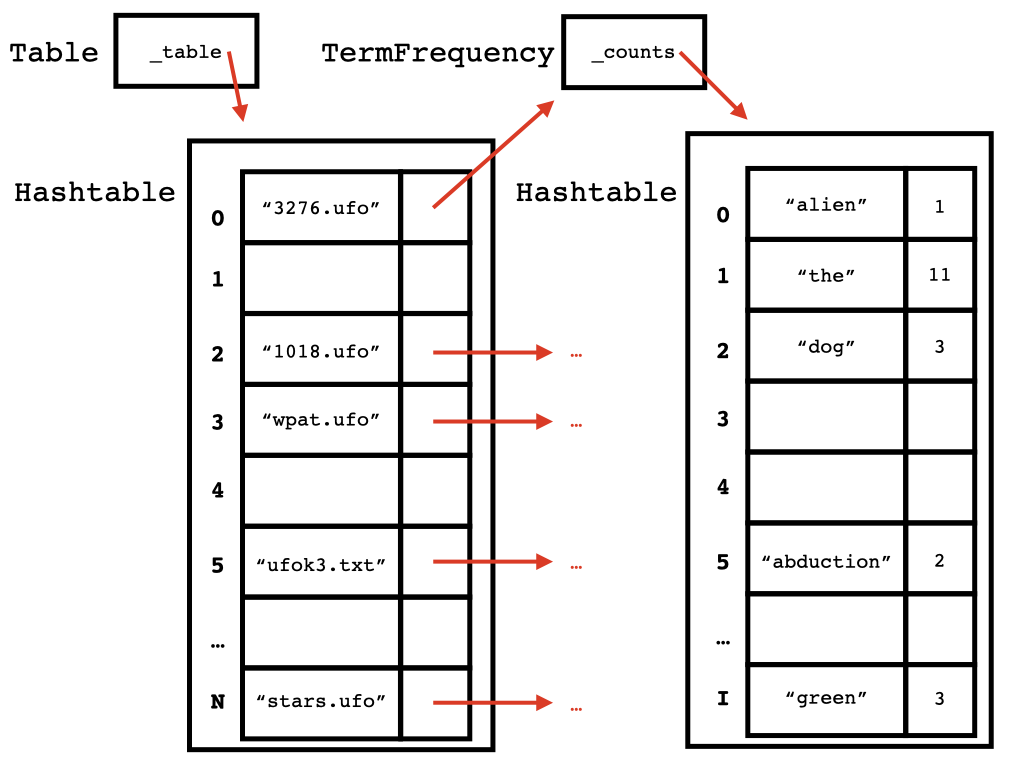
Once you have an index that stores term counts for each document, you will use the score method to assign a score to each document with respect to the given search query. This score determines the relevance of each document to the user’s query. Finally, your code will sort the documents by their relevance, and return the top \(k\) documents back to the user.
Term Frequency-Inverse Document Frequency
\(TF.IDF\), which stands for “term frequency-inverse document frequency,” is one approach to finding relevant documents without needing to resort to stop word removal or other hacks. The insight into \(TF.IDF\) is that words common to many documents are not very informative. Rare words—words that appear in few documents—on the other hand, are clearly used specific contexts and probably are informative. Therefore, rare words should carry more “weight” than common words when deciding which documents to return.
\(TF.IDF\) is the product of two statistics: term frequency and inverse document frequency, which we define below. You will need to implement the code that computes these statistics in the appropriate places in the assignment starter code.
Term Frequency
A term is another name for a word. The frequency of term \(i\) for document \(j\) is defined as:
In other words, frequency is simply the count of \(i\) in \(j\).
Term frequency is a statistic defined as:
In other words, \(TF_{i,j}\) is a number that says how frequent a given term \(i\) is relative to the most frequent term \(m\) in the same document \(j\). By this definition, the most frequent term in \(j\) will have a \(TF\) of \(1\), and all other terms will have lower \(TF\)s. A term that does not appear in a document at all will have a \(TF\) of \(0\).
Inverse Document Frequency
For a collection of \(N\) documents, the inverse document frequency is a statistic defined as:
where \(n_i\) is the number of documents in which term \(i\) appears at least once. \(IDF\) is a measure of how much information the word provides. If it’s common across all documents, then the \(IDF\) is a small number, whereas if it is rare, it is bigger.
TF.IDF and cumulative TF.IDF
The \(TF.IDF\) statistic is defined as:
The terms with the highest \(TF.IDF\) values best summarize the topic of document \(j\).
To determine the overall relevance of a document with respect to a search query, we now compute the cumulative \(TF.IDF\) for document \(j\), which is defined as
where \(q\) is a query and \(i\) is one of the terms in \(q\).
Finally, we can sort documents by their \(CTF.IDF\). The documents with the highest \(CTF.IDF\) will be the documents most relevant to the user’s query.
Using an algorithm that computes a \(CTF.IDF\) score for every document in the corpus helps, but we still haven’t reduced the amount of information given back to the user. We’ve just put it in sorted order. Most search engines therefore allow a user to provide a parameter, \(k\), which says how many of the “top \(k\)” results to return. For example, Google usually returns the top 5-10 documents by default.
Starter Code
This lab comes with starter code for the SearchEngine, Table, TermFrequency, and Term classes. You will need to finish these definitions to build a search engine.
SearchEngine
The SearchEngine class should contain your main method. It should allow a user to run the program as follows:
$ java SearchEngine "<query string>" <document folder path> <k>
where
<query string>is a search query, potentially composed of multiple terms,<document folder path>is a string representing the location of a document collection, and<k>is a positive integer representing how many documents to return.
In its main method, SearchEngine should first understand the user’s arguments, extract the search terms from the query, compute term counts for the documents in the given path, then compute the \(CTF.IDF\) score for each document given the query. Finally, it should generate a list of documents, sorted by their \(CTF.IDF\) score, and it should print out the top \(k\) most relevant documents back to the user.
To compute the overall top-\(k\) ranking, the SearchEngine class makes use of the Table class, which stores each document’s term counts.
Table
The Table class stores a mapping from documents to their term frequencies. It has the following methods, which you will need to write:
class Table {
public Table(Path dir); // constructor
public double idf(String term);
public Hashtable<String, Double> tfidf(String term);
public Hashtable<String, Double> score(Vector<String> query);
public Vector<Association<String, Double>> topK(Vector<String> query, int k);
}
Path objects, which can be used by importing java.nio.file.*, make working with paths easier, since paths on different operating systems (like Windows or the MacOS) are represented differently.
The Table class constructor should take a Path dir object that represents the path to a directory containing all of the files you would like to search. For every file in dir, a TermFrequency should be created. In other words, Table should index the files in dir. To obtain all of the files in a path, you may find the following (somewhat ugly) Java snippet to be very helpful:
Path[] files = Files.walk(dir).toArray(Path[]::new);
files is an array containing all of the Paths for every file in dir. You can then write a for loop to iterate through each file, e.g.,
Path[] files = Files.walk(dir).toArray(Path[]::new);
for (Path file : files) {
...
}
Note that some of the Paths in files will be sub-directories, so you should check to see which kind you are looking at using the File.isDirectory method.
Once Table is initialized, it can compute both the \(TF\) and \(IDF\) statistics, and using those two statistics, it can also compute the \(TF.IDF\) statistic for a given term. The score method returns the \(CTF.IDF\) for a given search query, which is a Vector<String> of terms.
The Table class should also be able to return the topK documents for a given query. To do this, you will need to sort documents. We encourage you to utilize the sorting techniques you have learned in previous labs (like using java.util.Comparator) in order to do this.
Finally, for debugging, we provide a toString method that converts a Table into comma-separated value (CSV) format. By saving this string to a file, a CSV file can be opened in the spreadsheet program of your choice (e.g, Microsoft Excel or OpenOffice Calc), which will make inspecting your data structure a bit easier.
/**
* Outputs frequency table in CSV format. Useful for
* debuggging.
*
* @param table A frequency table for the entire corpus.
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (String doc : _table.keySet()) {
TermFrequency docFreqs = _table.get(doc);
for (String term : docFreqs.terms()) {
sb.append("\"" + doc + "\",");
sb.append("\"" + term + "\",");
sb.append(docFreqs.getCount(term));
sb.append("\n");
}
}
return sb.toString();
}
For example, in your SearchEngine main method, if your Table is called table, you could write:
try {
PrintWriter writer = new PrintWriter("debug.csv");
writer.print(table);
writer.close();
} catch (FileNotFoundException e) {}
TermFrequency
The TermFrequency class tracks the frequency (count) of each term in a given document. It uses a structure5.Hashtable to store this mapping. TermFrequency has the following methods, which you will need to write:
class TermFrequency{
public TermFrequency(Path file); // constructor
public boolean isEmpty();
public double tf(String term);
public Association<String,Integer> mostFrequentTerm();
public int getCount(String term);
public Set<String> terms();
}
The TermFrequency constructor should take a Path object that points to a text file, and it should generate a mapping from every term in the file to the count of that term. Note that a String representation of a Path can be obtained by calling toString() on a Path object.
You can think of the given text file as a collection of words. These words should be read in and counted in the class. You may find the java.util.Scanner class useful for reading in terms. Be aware that terms must be normalized (see the Term class below) before you can reliably count them.
Since TermFrequency has all the information it needs to compute the \(TF\) statistic for a given term, it has a method tf that does this, and which the Table class should utilize when computing \(TF.IDF\).
Term class
The Term class contains two helpful methods, which you will need early on.
class Term {
public static Vector<String> toTerms(String query);
public static String normalize(String word);
}
The static toTerms method converts a query string like "How much does 1 dog eat?" into a Vector<String> of terms. To obtain a term, each word in the query needs to be normalized, meaning that uppercase characters, punctuation, and numbers are removed. Each term should only consist of the alphabetic characters [a-z].
Using our example query, toTerms should return the query vector ["how", "much", "does", "dog", "eat"]. Words that normalize to the empty string (e.g., "1") should be omitted from the query vector. You may find the java.util.Scanner class helpful in defining your toTerms method.
Expected Outputs
In your starter code, we provide two document collections. The first collection is a set of documents called ufo taken from the textfiles.com website (yes, these are wacky; no, we don’t endorse any of their contents). The second is a smaller subset called ufo-test. You may find the ufo-test collection to be easier to use since the full ufo collection may take several minutes to process.
For example, on the ufo-test collection, the following queries should output something like this:
$ java SearchEngine "Was Ronald Reagan an alien?" ufo-test 5
ufo-test/1174.ufo -> 0.3869765095166874
ufo-test/spacinv.ufo -> 0.24278778389424335
ufo-test/times.ufo -> 0.03222569937499169
ufo-test/unknown.ufo -> 0.026080496634970772
ufo-test/hypnoltrast.ufo -> 0.007387483580718654
(Here are extensive, gory debug outputs for the query above in case you are having trouble reproducing these outputs.)
$ java SearchEngine "Prime area for spotting UFO activity" ufo-test 5
ufo-test/vigil.ufo -> 0.13569651000086758
ufo-test/1174.ufo -> 0.038800673578030395
ufo-test/aus_gov.txt -> 0.02078562585244564
ufo-test/swampgas.ufo -> 0.015114616091221217
ufo-test/times.ufo -> 0.008351402759596376
$ java SearchEngine "Is there an air force cover up of aliens?" ufo-test 5
ufo-test/unknown.ufo -> 0.19387771907838655
ufo-test/vigil.ufo -> 0.035645201133296285
ufo-test/1174.ufo -> 0.008739102663429373
ufo-test/hypnoltrast.ufo -> -0.004174434589321152
ufo-test/times.ufo -> -0.0062869101432885335
$ java SearchEngine "Isn't Beyonce the best?" ufo-test 5
ufo-test/hypnoltrast.ufo -> -0.08322334893224118
ufo-test/times.ufo -> -0.08473243068431324
ufo-test/genesis.ufo -> -0.11959666195440723
ufo-test/unknown.ufo -> -0.13750352374993513
ufo-test/1174.ufo -> -0.13750352374993513
Run these queries on the entire corpus. What are your results? Then come up with a 2-3 more queries of your own design and run those too. What do you learn?
Optional Extensions
Once you have a working search engine, a few new possibilities open up. Note that these are optional extras, for bonus credit. Try them if you want to push yourself, otherwise you can skip them.
Optional: Make Indexing Faster
Our implementation is somewhat inefficient because it needs to compute \(TF.IDF\) every time the user provides a query. Although \(CTF.IDF\) depends on a specific user query, \(TF.IDF\) only depends on the terms found in the corpus. As such, these terms can be counted “offline”, stored in a Table, and then written to disk.
Extend your SearchEngine class in a new Java file called CachedSearchEngine.
When the user first runs SearchEngine, before the query is run, a Table is computed and then written to a file. The next time a user runs SearchEngine, the program first checks to see whether there is a saved Table. If so, it reads the Table from the saved file instead of scanning through the files in the document collection.
You might consider using the handy Table.toString method we provided earlier as inspiration for your disk format.
Optional: Indexing the Web
Of course, real search engines don’t stop with indexing files on one computer, they fetch files on the Internet and index those as well.
Extend your SearchEngine class in a new Java file called WebSearchEngine.
You will want to modify your class so that it:
- Takes a count of how many webpages to index;
- Takes a starting “seed” URL;
- Fetches a webpage from from the URL, and indexes it, storing the URL as the document name;
- Then uses the URLs found on each fetched webpage as the “seed” URLs to fetch more pages (i.e., go to step 3);
- Repeats this process until it runs out of URLs or it exceeds the count given by the user.
Use the jsoup Java library which provides convenient methods for fetching and parsing HTML webpages. Note that you will probably find it easiest to get started by download the jsoup JAR file. You will need to include the -cp jsoup-1.13.1.jar flag both when compiling with javac as well as when running with java.
Thought Questions
In addition, answer the following questions in a file called PROBLEMS.md, and submit it with the rest of your code this lab.
- In the
WordGenlab, you implemented map using aVector<Association<...>>. Why is aHashtablea superior data structure? Compare the asymptotic costs of runningSearchEnginewhen using either data structure. - In this lab, hash table keys were
Strings, which are already designed to work as hash table keys. How would you have to modify an arbitrary class if you wanted to use it as a key in a hash table? You may have to do a little research on your own here to determine how Java hashes an arbitrary key.
Lab Deliverables
We provide basic starter code for this assignment. The starter code contains the following files:
| Filename | Purpose |
|---|---|
SearchEngine.java |
The driver class for this program. |
Table.java |
Class that stores a map from file names to term frequencies. |
TermFrequency.java |
Class that stores a map from terms to counts. |
Term.java |
Helper methods for working with terms. |
ufo, ufo-test |
Data files containing sets of words for testing purposes. |
You should see a new private repository called cs136lab08_mooogle-{USERNAMES} in your GitHub account (where USERNAMES is replaced by your usernames).
For this lab, please submit the following:
cs136lab08_mooogle-{USERNAMES}/
README.md
PROBLEMS.md
SearchEngine.java
Table.java
TermFrequency.java
Term.java
ufo/
...
ufo-test/
...
where SearchEngine.java, Table.java, TermFrequency.java, and Term.java should contain your well-documented source code. You may find it useful to create additional classes, and you are encouraged to do so. Please be sure to include those additional files when submitting your code.
As in all labs, you will be graded on design, documentation, and functionality. Be sure to document your program with appropriate comments, a general description at the top of the file, and a description of each method with pre- and post-conditions where appropriate. Also use comments and descriptive variable names to clarify sections of the code which may not be clear to someone trying to understand it.
Whenever you see yourself duplicating functionality, consider moving that code to a helper method. There are several opportunities in this lab to simplify your code by using helper methods.
Submitting Your Lab
As you complete portions of this lab, you should commit your changes and push them. Commit early and often. When you are confident that you are done, please use the phrase "Lab Submission" as the commit message for your final commit and check the box on the README.md file to indicate that you are done. If you later decide that you have more edits to make, it is OK. We will look at the latest commit.
- Be sure to push your changes to GitHub.
- Verify your changes on Github. Navigate in your web browser to your private repository on GitHub. You should see all changes reflected in the files that you
push. If not, go back and make sure you have both committed and pushed.
We will know that the files are yours because they are in your git repository. Do not include identifying information in the code that you submit. We grade your lab programs anonymously to avoid bias. In your README.md file, please cite any sources of inspiration or collaboration (e.g., conversations with classmates). We take the honor code very seriously, and so should you. Please include the statement "We are the sole authors of the work in this repository." in the comments at the top of your Java files.
The squeaky wheel gets the grease
We are always looking to make our labs better. Please submit answers to the following questions using the anonymous feedback form for this class:
- How difficult was this assignment on a scale from 1 to 5 (1 = super easy, …, 5 = super hard).
- Anything else that you want to tell us?
Bonus: Mistakes
This is a new lab! So it probably has lots of mistakes!
Did you find any mistakes in this writeup? If so, add a file called MISTAKES.md to your GitHub repository and describe the mistakes using bullets. For example, you might write
* Where it says "bypass the auxiliary sensor" you should have written "bypass the primary sensor".
* You spelled "college" wrong ("collej").
* A quadrilateral has four edges, not "too many to count" as you state.
You will receive 1 bonus point on this assignment for each mistake we are able to validate. –>